![]()
[Jan-2024] DEA-C01 Free Sample Questions to Practice One Year Update
Download DEA-C01 exam with Snowflake DEA-C01 Real Exam Questions
NEW QUESTION # 32
Does sensitive data in Snowflake is modified in an existing table while applying Masking policies?
- A. YES
- B. NO
Answer: B
Explanation:
Explanation
Snowflake supports masking policies as a schema-level object to protect sensitive data from unau-thorized access while allowing authorized users to access sensitive data at query runtime. This means that sensitive data in Snowflake is not modified in an existing table (i.e. no static masking). Rather, when users execute a query in which a masking policy applies, the masking policy condi-tions determine whether unauthorized users see masked, partially masked, obfuscated, or tokenized data.
NEW QUESTION # 33
Which are supported Programming Languages for Creating UDTFs?
- A. Node.javascript
- B. Python
- C. Javascript
- D. Perl
- E. Java
Answer: B,C,E
NEW QUESTION # 34
As Data Engineer, you have requirement to Load set of New Product Files containing Product rele-vant information into the Snowflake internal tables, Later you analyzed that some of the Source files are already loaded in one of the historical batch & for that you have prechecked Metadata col-umn LAST_MODIFIED date for a staged data file & found out that LAST_MODIFIED date is older than 64 days for few files and the initial set of data was loaded into the table more than 64 days earlier, Which one is the best approach to Load Source data files with expired load metadata along with set of files whose metadata might be available to avoid data duplication?
- A. Since the initial set of data for the table (i.e. the first batch after the table was created) was loaded, we can simply use the COPY INTO command to load all the product files with the known load status irrespective of their column LAST_MODIFIED date values.
- B. To load files whose metadata has expired, set the LOAD_UNCERTAIN_FILES copy option to true.
- C. The COPY command cannot definitively determine whether a file has been loaded al-ready if the LAST_MODIFIED date is older than 64 days and the initial set of data was loaded into the table more than 64 days earlier (and if the file was loaded into the table, that also occurred more than 64 days earlier). In this case, to prevent accidental reload, the command skips the product files by default.
- D. Set the FORCE option to load all files, ignoring load metadata if it exists.
Answer: B
Explanation:
Explanation
To load files whose metadata has expired, set the LOAD_UNCERTAIN_FILES copy option to true. The copy option references load metadata, if available, to avoid data duplication, but also at-tempts to load files with expired load metadata.
Alternatively, set the FORCE option to load all files, ignoring load metadata if it exists. Note that this option reloads files, potentially duplicating data in a table.
Please refer the Example as mentioned in the link below:
https://docs.snowflake.com/en/user-guide/data-load-considerations-load.html#loading-older-files
NEW QUESTION # 35
Data Engineer looking out for quick tool for understanding the mechanics of queries & need to know more about the performance or behaviour of a particular query.
He should go to which feature of snowflake which can help him to spot typical mistakes in SQL query expressions to identify potential performance bottlenecks and improvement opportunities?
- A. Query Designer
- B. Query Optimizer
- C. Query Profile
- D. Performance Metadata table
Answer: C
Explanation:
Explanation
Query Profile, available through the classic web interface, provides execution details for a query. For the selected query, it provides a graphical representation of the main components of the pro-cessing plan for the query, with statistics for each component, along with details and statistics for the overall query.
Query Profile is a powerful tool for understanding the mechanics of queries. It can be used whenev-er you want or need to know more about the performance or behavior of a particular query. It is de-signed to help you spot typical mistakes in SQL query expressions to identify potential performance bottlenecks and improvement opportunities.
NEW QUESTION # 36
If the data retention period for a table is less than 90 days, and a stream has not been consumed, Snowflake temporarily extends this period to prevent it from going stale?
- A. FALSE
- B. TRUE
Answer: A
Explanation:
Explanation
If the data retention period for a table is less than 14 days, and a stream has not been consumed, Snowflake temporarily extends this period to prevent it from going stale. The period is extended to the stream's offset, up to a maximum of 14 days by default, regardless of the Snowflake edition for your account. The maximum number of days for which Snowflake can extend the data retention period is determined by the MAX_DATA_EXTENSION_TIME_IN_DAYS parameter value. When the stream is consumed, the extended data retention period is reduced to the default period for the table.
NEW QUESTION # 37
To view/monitor the clustering metadata for a table, Snowflake provides which of the following system functions?
- A. SYSTEM$CLUSTERING_DEPTH
- B. SYSTEM$CLUSTERING_KEY_INFORMATION (including clustering depth)
- C. SYSTEM$CLUSTERING_INFORMATION (including clustering depth)
- D. SYSTEM$CLUSTERING_DEPTH_KEY
Answer: A,C
Explanation:
Explanation
SYSTEM$CLUSTERING_DEPTH:
Computes the average depth of the table according to the specified columns (or the clustering key defined for the table). The average depth of a populated table (i.e. a table containing data) is always 1 or more. The smaller the average depth, the better clustered the table is with regards to the speci-fied columns.
Calculate the clustering depth for a table using two columns in the table:
SELECT SYSTEM$CLUSTERING_DEPTH('TPCH_PRODUCT', '(C2, C9)');
SYSTEM$CLUSTERING_INFORMATION:
Returns clustering information, including average clustering depth, for a table based on one or more columns in the table.
SELECT SYSTEM$CLUSTERING_INFORMATION('SAMPLE_TABLE', '(col1, col3)');
NEW QUESTION # 38
The following chart represents the performance of a virtual warehouse over time: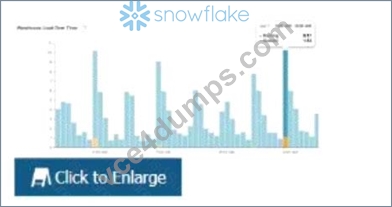
A DataEngineer notices that the warehouse is queueing queries The warehouse is size X-Smallthe minimum and maximum cluster counts are set to 1 the scaling policy is set to i and auto-suspend is set to 10 minutes.
How canthe performance be improved?
- A. Change the scaling policy to economy
- B. Increase the size of the warehouse
- C. Change auto-suspend to a longer time frame
- D. Change the cluster settings
Answer: B
Explanation:
Explanation
The performance can be improved by increasing the size of the warehouse. The chart shows that the warehouse is queueing queries, which means that there are more queries than the warehouse can handle at its current size. Increasing the size of the warehouse will increase its processing power and concurrency limit, which could reduce the queueing time and improve the performance. The other options are not likely to improve the performance significantly. Option A, changing the cluster settings, will not help unless the minimum and maximum cluster countsare increased to allow for multi-cluster scaling. Option C, changing the scaling policy to economy, will not help because it will reduce the responsiveness of the warehouse to scale up or down based on demand. Option D, changing auto-suspend to a longer time frame, will not help because it will only affect how long the warehouse stays idle before suspending itself.
NEW QUESTION # 39
1.+--------------------------------------------------------------+
2.| SYSTEM$CLUSTERING_INFORMATION('SF_DATA', '(COL1, COL3)') |
3.|--------------------------------------------------------------|
4.| { |
5.| "cluster_by_keys" : "(COL1, COL3)", |
6.| "total_partition_count" : 1156, |
7.| "total_constant_partition_count" : 0, |
8.| "average_overlaps" : 117.5484, |
9.| "average_depth" : 64.0701, |
10.| "partition_depth_histogram" : { |
11.| "00000" : 0, |
12.| "00001" : 0, |
13.| "00002" : 3, |
14.| "00003" : 3, |
15.| "00004" : 4, |
16.| "00005" : 6, |
17.| "00006" : 3, |
18.| "00007" : 5, |
19.| "00008" : 10, |
20.| "00009" : 5, |
21.| "00010" : 7, |
22.| "00011" : 6, |
23.| "00012" : 8, |
24.| "00013" : 8, |
25.| "00014" : 9, |
26.| "00015" : 8, |
27.| "00016" : 6, |
28.| "00032" : 98, |
29.| "00064" : 269, |
30.| "00128" : 698 |
31.| } |
32.| } |
33.+--------------------------------------------------------------+
The Above example indicates that the SF_DATA table is not well-clustered for which of following valid reasons?
- A. Most of the micro-partitions are grouped at the lower-end of the histogram, with the majority of micro-partitions having an overlap depth between 64 and 128.
- B. High average of overlapping micro-partitions.
- C. ALL of the above
- D. Zero (0) constant micro-partitions out of 1156 total micro-partitions.
- E. High average of overlap depth across micro-partitions.
Answer: C
NEW QUESTION # 40
For the most efficient and cost-effective Data load experience, Data Engineer needs to inconsider-ate which of the following considerations?
- A. if the "null" values in your files indicate missing values and have no other special mean-ing, Snowflake recommend setting the file format option STRIP_NULL_VALUES to TRUE when loading the semi-structured data file.
- B. When preparing your delimited text (CSV) files for loading, the number of columns in each row should be consistent.
- C. Amazon Kinesis Firehose can be convenient way to aggregate and batch data files which also allows defining both the desired file size, called the buffer size, and the wait interval after which a new file is sent, called the buffer interval.
- D. Split larger files into a greater number of smaller files, maximize the processing over-head for each file.
(Correct) - E. Enabling the STRIP_OUTER_ARRAY file format option for the COPY INTO <ta-ble> command to remove the outer array structure and load the records into separate table rows.
Answer: D
Explanation:
Explanation
Split larger files into a greater number of smaller files to distribute the load among the compute re-sources in an active warehouse. This would minimize the processing overhead rather than maximize it.
Rest is recommended Data loading considerations.
NEW QUESTION # 41
Which of the following statements is/are incorrect regarding Fail-safe data recovery?
- A. Historical data in transient tables can be recovered by Snowflake due to Operation fail-ure after the Time Travel retention period ends using Fail-safe.
- B. Long-lived tables, such as fact tables, should always be defined as permanent to ensure they are fully protected by Fail-safe.
- C. Short-lived tables (i.e. <1 day), such as ETL work tables, can be defined as transient to eliminate Fail-safe costs.
- D. Data stored in temporary tables is not recoverable after the table is dropped as they do not have fail-safe.
- E. If downtime and the time required to reload lost data are factors, permanent tables, even with their added Fail-safe costs, may offer a better overall solution than transient tables.
Answer: A
NEW QUESTION # 42
To troubleshoot data load failure in one of your Copy Statement, Data Engineer have Executed a COPY statement with the VALIDATION_MODE copy option set to RETURN_ALL_ERRORS with reference to the set of files he had attempted to load. Which below function can facilitate analysis of the problematic records on top of the Results produced? [Select 2]
- A. RESULT_SCAN
- B. Rejected_record
- C. LOAD_ERROR
- D. LAST_QUERY_ID
Answer: A,D
Explanation:
Explanation
LAST_QUERY_ID() Function
Returns the ID of a specified query in the current session. If no query is specified, the most recently executed query is returned.
RESULT_SCAN() Function
Returns the result set of a previous command (within 24 hours of when you executed the query) as if the result was a table.
The following example validates a set of files (SFfile.csv.gz) that contain errors. To facilitate analy-sis of the errors, a COPY INTO <location> statement then unloads the problematic records into a text file so they could be analyzed and fixed in the original data files. The statement queries the RESULT_SCAN table.
1.#copy into Snowtable
2.from @SFstage/SFfile.csv.gz
3.validation_mode=return_all_errors;
4.#set qid=last_query_id();
5.#copy into @SFstage/errors/load_errors.txt from (select rejected_record from ta-ble(result_scan($qid))); Note: Other options are not valid functions.
NEW QUESTION # 43
Mark the incorrect statement when Data Engineer implement Automating Continuous Data Loading Using Cloud Messaging?
- A. Notifications identify the cloud storage event and include a list of the file names. They do not include the actual data in the files.
- B. Automated Snowpipe uses event notifications to determine when new files arrive in monitored cloud storage and are ready to load.
- C. Triggering automated Snowpipe data loads using S3 event messages is supported by Snowflake accounts hosted on Cloud Platform like AWS, GCP or AZURE.
- D. When a pipe is paused, event messages received for the pipe enter a limited retention period. The period is 14 days by default. If a pipe is paused for longer than 14 days, it is considered stale.
Answer: C
Explanation:
Explanation
Triggering automated Snowpipe data loads using S3 event messages is supported by Snowflake ac-counts hosted on Amazon Web Services (AWS) only.
Rest is correct statements.
NEW QUESTION # 44
For enabling non-ACCOUNTADMIN Roles to Perform Data Sharing Tasks, which two glob-al/account privileges snowflake provide?
- A. CREATE SHARE
- B. OPERATE
- C. IMPORT SHARE
- D. REFERENCE USAGE
Answer: A,C
Explanation:
Explanation
CREATE SHARE
In a provider account, this privilege enables creating and managing shares (for sharing data with consumer accounts).
IMPORT SHARE
In a consumer account, this privilege enables viewing the inbound shares shared with the account. Also enables creating databases from inbound shares; requires the global CREATE DATABASE privilege.
By default, these privileges are granted only to the ACCOUNTADMIN role, ensuring that only ac-count administrators can perform these tasks. However, the privileges can be granted to other roles, enabling the tasks to be delegated to other users in the account.
NEW QUESTION # 45
Which is the non-supportable JavaScript UDF data types?
- A. String
- B. Double
- C. Binary
- D. Integers
Answer: D
NEW QUESTION # 46
Snowpipe API provides a REST endpoint for defining the list of files to ingest that Informs Snow-flake about the files to be ingested into a table. A successful response from this endpoint means that Snowflake has recorded the list of files to add to the table. It does not necessarily mean the files have been ingested. What is name of this Endpoint?
- A. REST endpoints --> loadHistoryScan
- B. REST endpoints --> insertReport
- C. REST endpoints--> insertfiles
- D. REST endpoints --> ingestfiles
Answer: C
Explanation:
Explanation
The Snowpipe API provides a REST endpoint for defining the list of files to ingest.
Endpoint: insertFiles
Informs Snowflake about the files to be ingested into a table. A successful response from this end-point means that Snowflake has recorded the list of files to add to the table. It does not necessarily mean the files have been ingested. For more details, see the response codes below.
In most cases, Snowflake inserts fresh data into the target table within a few minutes.
To Know more about SnowFlake Rest API used for Data File ingestion, do refer:
https://docs.snowflake.com/en/user-guide/data-load-snowpipe-rest-apis.html#data-file-ingestion
NEW QUESTION # 47
A Data Engineer needs to ingest invoice data in PDF format into Snowflake so that the data can be queried and used in a forecasting solution.
..... recommended way to ingest this data?
- A. Create an external table on the PDF files that are stored in a stage and parse the data nto structured data
- B. Create a Java User-Defined Function (UDF) that leverages Java-based PDF parser libraries to parse PDF data into structured data
- C. Use a COPY INTO command to ingest the PDF files in an external stage into a Snowflake table with a VARIANT column.
- D. Use Snowpipe to ingest the files that land in an external stage into a Snowflake table
Answer: B
Explanation:
Explanation
The recommended way to ingest invoice data in PDF format into Snowflake is to create a Java User-Defined Function (UDF) that leverages Java-based PDF parser libraries to parse PDF data into structured data. This option allows for more flexibility and control over how the PDF data is extracted and transformed. The other options are not suitable for ingesting PDF data into Snowflake. Option A and B are incorrect because Snowpipe and COPY INTO commands can only ingest files that are in supported file formats, such as CSV, JSON, XML, etc. PDF files are not supported by Snowflake and will cause errors or unexpected results.
Option C is incorrect because external tables can only query files that are in supported file formats as well.
PDF files cannot be parsed by external tables and will cause errors or unexpected results.
NEW QUESTION # 48
A Data Engineer has developed a dashboard that will issue the same SQL select clause to Snowflake every 12 hours.
---will Snowflake use the persisted query results from the result cache provided that the underlying data has not changed^
- A. 24 hours
- B. 31 days
- C. 14 days
- D. 12 hours
Answer: C
Explanation:
Explanation
Snowflake uses the result cache to store the results of queries that have been executed recently. The result cache is maintained at the account level and is shared across all sessions and users. The result cache is invalidated when any changes are made to the tables or views referenced by the query. Snowflake also has a retention policy for the result cache, which determines how long the results are kept in the cache before they are purged. The default retention period for the result cache is 24 hours, but it can be changed at the account, user, or session level. However, there is a maximum retention period of 14 days for the result cache, which cannot be exceeded. Therefore, if the underlying data has not changed, Snowflake will use the persisted query results from the result cache for up to 14 days.
NEW QUESTION # 49
Mark the Correct Statements:
Statement 1. Snowflake's zero-copy cloning feature provides a convenient way to quickly take a "snapshot" of any table, schema, or database.
Statement 2. Data Engineer can use zero-copy cloning feature for creating instant backups that do not incur any additional costs (until changes are made to the cloned object).
- A. Both are False.
- B. Statement 1 & 2 are correct.
- C. Statement 2
- D. Statement 1
Answer: A
Explanation:
Explanation
Snowflake's zero-copy cloning feature provides a convenient way to quickly take a "snapshot" of any table, schema, or database and create a derived copy of that object which initially shares the underlying storage. This can be extremely useful for creating instant backups that do not incur any additional costs (until changes are made to the cloned object).
For example, when a clone is created of a table, the clone utilizes no data storage because it shares all the existing micro-partitions of the original table at the time it was cloned; however, rows can then be added, deleted, or updated in the clone independently from the original table. Each change to the clone results in new micro-partitions that are owned exclusively by the clone and are protect-ed through CDP.
NEW QUESTION # 50
To advance the offset of a stream to the current table version without consuming the change data in a DML operation, which of the following operations can be done by Data Engineer? [Select 2]
- A. Delete the offset using STREAM properties SYSTEM$RESET_OFFSET( <stream_id> )
- B. A stream advances the offset only when it is used in a DML transaction, so none of the options works without consuming the change data of table.
- C. Insert the current change data into a temporary table. In the INSERT statement, query the stream but include a WHERE clause that filters out all of the change data (e.g. WHERE 0 = 1).
- D. using the CREATE OR REPLACE STREAM syntax, Recreate the STREAM
Answer: C,D
Explanation:
Explanation
When created, a stream logically takes an initial snapshot of every row in the source object (e.g. ta-ble, external table, or the underlying tables for a view) by initializing a point in time (called an off-set) as the current transactional version of the object. The change tracking system utilized by the stream then records information about the DML changes after this snapshot was taken. Change rec-ords provide thestate of a row before and after the change. Change information mirrors the column structure of the tracked source object and includes additional metadata columns that describe each change event.
Note that a stream itself does not contain any table data. A stream only stores an offset for the source object and returns CDC records by leveraging the versioning history for the source object.
A new table version is created whenever a transaction that includes one or more DML statements is committed to the table.
In the transaction history for a table, a stream offset is located between two table versions. Query-ing a stream returns the changes caused by transactions committed after the offset and at or before the current time.
Multiple queries can independently consume the same change data from a stream without changing the offset.
A stream advances the offset only when it is used in a DML transaction. This behavior applies to both explicit and autocommit transactions. (By default, when a DML statement is execut-ed, an autocommit transaction is implicitly started and the transaction is committed at the comple-tion of the statement. This behavior is controlled with the AUTOCOMMIT parameter.) Querying a stream alone does not advance its offset, even within an explicit transaction; the stream contents must be consumed in a DML statement.
To advance the offset of a stream to the current table version without consuming the change data in a DML operation, complete either of the following actions:
Recreate the stream (using the CREATE OR REPLACE STREAM syntax).
Insert the current change data into a temporary table. In the INSERT statement, query the stream but include a WHERE clause that filters out all of the change data (e.g. WHERE 0 = 1).
NEW QUESTION # 51
Which property can be used with ALTER USER command to temporarily disable MFA for the user so that they can log in?
- A. HOURS_TO_BYPASS_MFA
- B. MINS_TO_BYPASS_MFA
- C. MINS_TO_SKIP_MFA
- D. SECS_TO_BYPASS_MFA
Answer: B
Explanation:
Explanation
You can use the following properties for the ALTER USER command to perform these tasks:
MINS_TO_BYPASS_MFA
Specifies the number of minutes to temporarily disable MFA for the user so that they can log in. Af-ter the time passes, MFA is enforced and the user cannot log in without the temporary token gener-ated by the Duo Mobile application.
NEW QUESTION # 52
As a Data Engineer, you have requirement to query most recent data from the Large Dataset that reside in the external cloud storage, how would you design your data pipelines keeping in mind fastest time to delivery?
- A. Data pipelines would be created to first load data into internal stages & then into Per-manent table with SCD Type 2 transformation.
- B. Unload data into SnowFlake Internal data storage using PUT command.
- C. Direct Querying External tables on top of existing data stored in external cloud storage for analysis without first loading it into Snowflake.
- D. Snowpipe can be leveraged with streams to load data in micro batch fashion with CDC streams that capture most recent data only.
- E. External tables with Materialized views can be created in Snowflake.
Answer: E
Explanation:
Explanation
In a typical table, the data is stored in the database; however, in an external table, the data is stored in files in an external stage. External tables store file-level metadata about the data files, such as the filename, a version identifier and related properties. This enables querying data stored in files in an external stage as if it were inside a database. External tables can access data stored in any format supported by COPY INTO <table> statements.
External tables are read-only, therefore no DML operations can be performed on them; however, external tables can be used for query and join operations. Views can be created against external ta-bles.
Querying data stored external to the database is likely to be slower than querying native database tables; however, materialized views based on external tables can improve query performance.
Creating External tables enable user for querying existing data stored in external cloud storage for analysis without first loading it into Snowflake. The source of truth for the data remains in the ex-ternal cloud storage.
Data sets materialized in Snowflake via materialized views are read-only.
This solution is especially beneficial to accounts that have a large amount of data stored in external cloud storage and only want to query a portion of the data; for example, the most recent data. Users can create materialized views on subsets of this data for improved query performance.
NEW QUESTION # 53
Which one is not the Core benefits of micro-partitioning
- A. Snowflake micro-partitions are derived automatically they do not need to be explicitly defined up-front or maintained by users.
- B. Columns are stored independently within micro-partitions, often referred to as colum-nar storage.
- C. Columns are also compressed individually within micro-partitions.
- D. Micro-partitions can overlap in their range of values, helps data skewing.
- E. Enables extremely efficient DML and fine-grained pruning for faster queries.
Answer: D
Explanation:
Explanation
The benefits of Snowflake's approach to partitioning table data include:
In contrast to traditional static partitioning, Snowflake micro-partitions are derived automatically; they don't need to be explicitly defined up-front or maintained by users.
As the name suggests, micro-partitions are small in size (50 to 500 MB, before compression), which enables extremely efficient DML and fine-grained pruning for faster queries.
Micro-partitions can overlap in their range of values, which, combined with their uniformly small size, helps prevent skew.
Columns are stored independently within micro-partitions, often referred to as columnar storage. This enables efficient scanning of individual columns; only the columns referenced by a query are scanned.
Columns are also compressed individually within micro-partitions. Snowflake automatically de-termines the most efficient compression algorithm for the columns in each micro-partition.
NEW QUESTION # 54
......
Real exam questions are provided for SnowPro Advanced tests, which can make sure you 100% pass: https://www.vce4dumps.com/DEA-C01-valid-torrent.html
DEA-C01 Exam with Guarantee Updated 67 Questions: https://drive.google.com/open?id=1tUp9nPLA01C5QpeU6vLBSApekzcPldlE